
Research
Scientific machine learning (SciML) promises to revolutionize our understanding of complex science and engineering problems. Rather than constructing mathematical models using trial-and-error human intuition, SciML aims to efficiently uncover quantitatively accurate descriptions directly from data. However, the actual scope of scientific discovery achieved through machine learning remains modest; there is a large gap between the wealth of empirical expertise in learning from relatively unorganized data vs. the centuries of essential domain knowledge describing the structure of real-world physical systems. My work aims to develop tools that better bridge this gap.
Sparse Physics-Informed Discovery of Empirical Relations (SPIDER)
Historically, partial differential equations (PDEs) have been one of the primary languages for writing down the governing laws of physical systems. My doctoral dissertation addresses the problem of automating the discovery of complete PDE models from experimental measurements. Unlike other approaches, SPIDER identifies tensor-valued equations that explicitly respect the symmetries of the system. Moreover, it furnishes a systematic procedure for constructing and manipulating symbolic tensor expressions using a custom computer algebra system. This allows SPIDER to search the space of possible relations exhaustively and expand the set of learned equations by deductive reasoning, requiring only minimal user guidance.
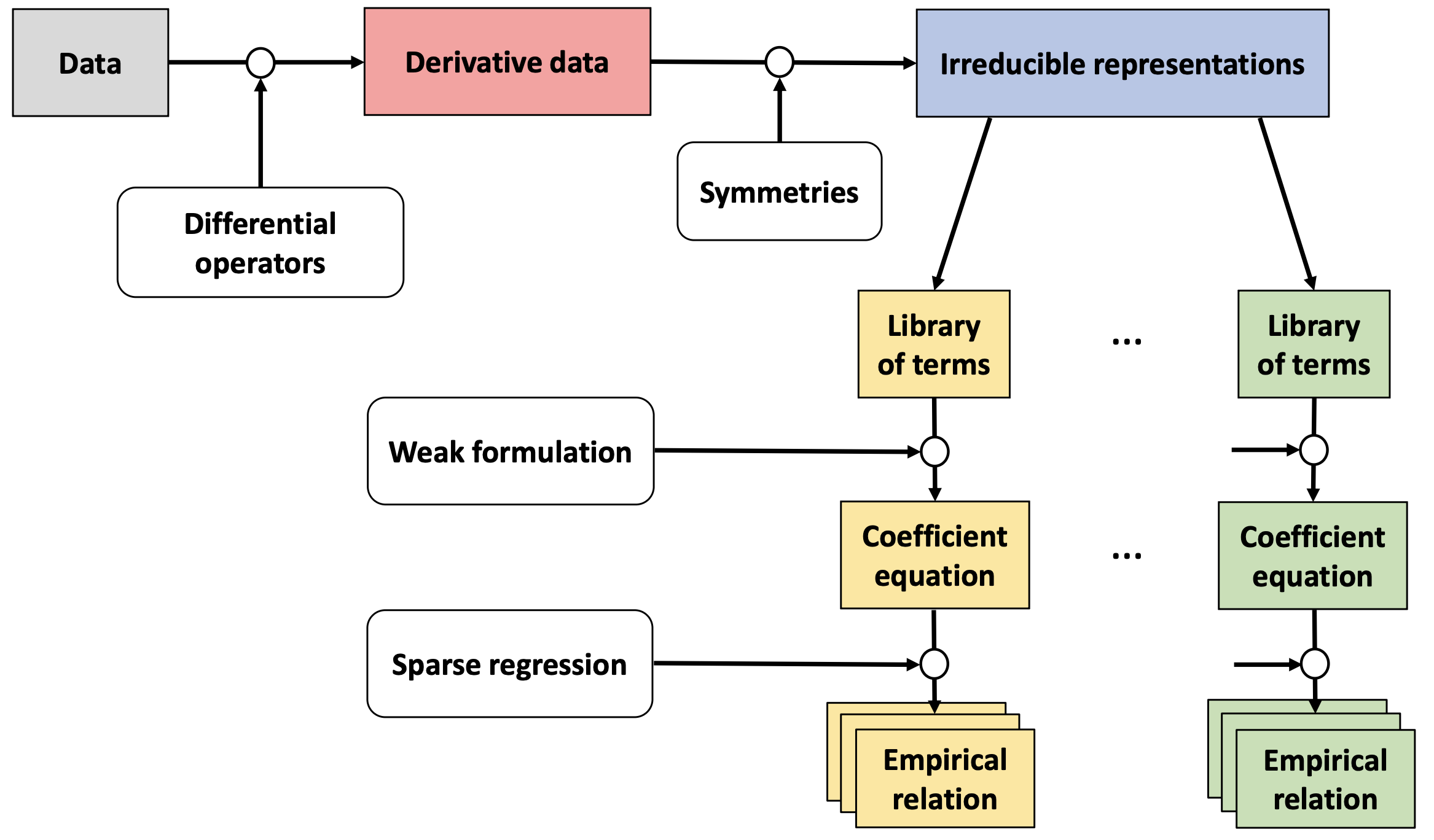
SPIDER is freely available on GitHub. Please shoot me an email if you have any questions or need help getting set up!
Multiscale attention
Real-world data generally contain hierarchical multiscale structures that are essential to proper interpretation. For instance, fluid turbulence is characterized by self-similar vortices spanning length scales across multiple orders of magnitude, while its molecular description involves both rapid thermal fluctuations and much slower coherent flow patterns.
At the same time, transformers have emerged as one of the dominant architectures for modeling temporal data, even though they have notoriously poor computational scaling for long sequences and tend to “forget” long-range correlations. (For instance, in language modeling, they may achieve high accuracy on a sentence or paragraph level, but not necessarily in modeling the meaning across chapters.) In this project, I am developing machine learning models that are intrinsically hierarchical and self-similar, learning features of the data across all relevant scales and efficiently mixing information across these scales.